NER 任务分为三类,目前来说,各个子任务目前都有方法可以一定程度上解决,但缺少一个方法可以同时解决三个任务。下图分别介绍了三个子任务的常见解决方案
- Flat NER(扁平实体抽取):通常采用序列标注的方法
- Nested NER(嵌套实体抽取):将输入文本采用类似 n-gram 的方法进行拆分,拆成一个个小的 span 后进行分类
- Discontinous NER(非连续实体抽取):用一个堆栈,为每个 token 选择移入移出规约等操作,类似于编译器生成 AST 的过程,详见另一篇论文
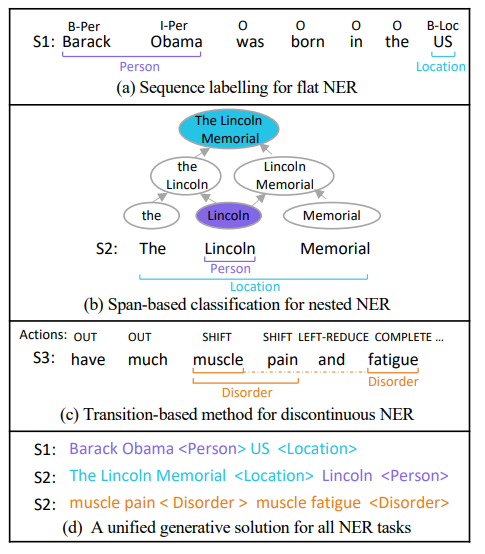
这篇文章提出使用 seq2seq 的框架以生成的方式来同时完成三个任务,也就是标题中的那个可用于各种 NER 子任务的通用框架。输出形式则为上图中的 (d),通过生成的方式输出实体的内容,最后以一个指示实体类型的特殊标签作为该实体的结束,并以同样的方式生成下一个实体。
模型结构
模型整体结构较为简单,为了让模型更好的完成生成任务,文中采用预训练过的 seq2seq 模型 BART 作为基础。输入为一段文本(首尾加上了特殊 token),输出时采用指针网络的方式,输出在输入中的位置。
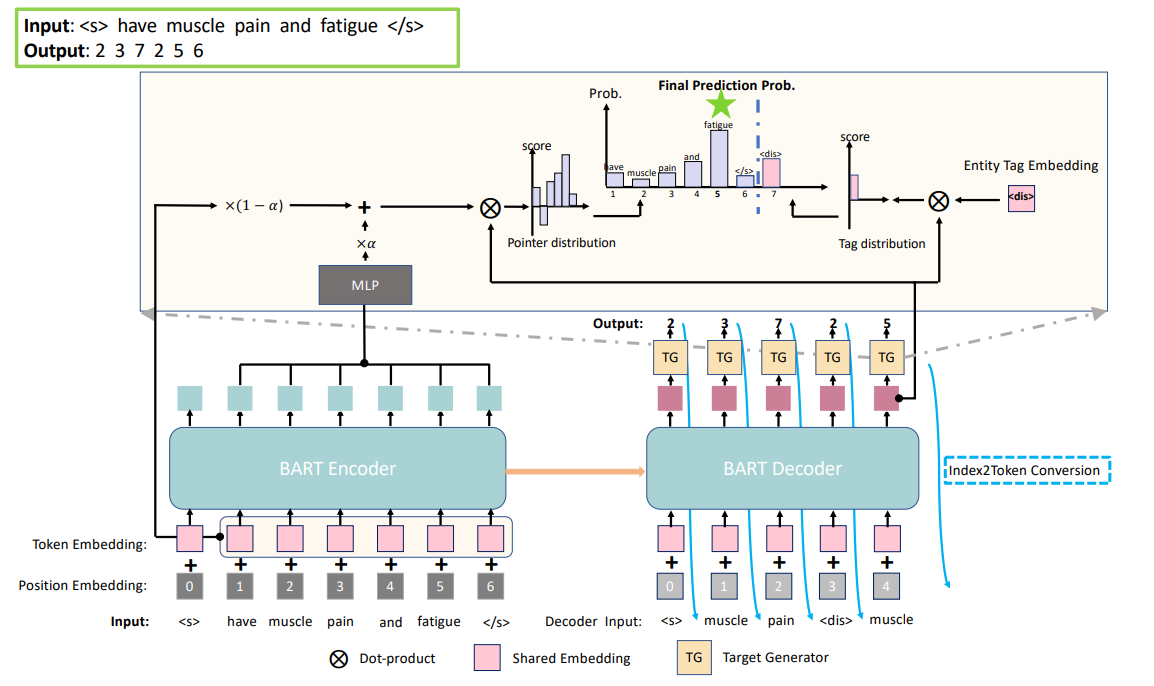
具体来说,模型沿用了 BART 的 encoder-decoder 的架构(下半部分),主要工作在如何生成字符(上半部分)。
模型通过 encoder 和 decoder 后,分别拿到了两个隐状态 \(H^e\) 和 \(h_t^d\)。
实际中,index 并不能直接输入 decoder,所以解码器中还进行了一步 index2token,以 token 的方式输入
之后作者将 \(H^e\) 通过一层 MLP 后与输入的 Token Embedding 加权相加(公式 7)得到 \(\overline{H}^e\)。
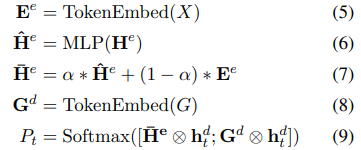
然后模型会计算一个 Pointer Distribution 和 Tag Distribution,即文中每个位置(指针)的概率分布和标签的概率分布,两者合在一起就是图中的 Final Prediction Prob.,从中选择概率最高的也就是这一步输出的结果。
实际上,就是将 \(\overline{H}^e\) 和 tag 的 embedding 后的输出 \(G^d\) 分别与 decoder 的输出 \(h_t^d\) 相乘后拼接(公式 9),通过 softmax 找到概率最大的,作为输出。
然后就以自回归的方式不断重复上述步骤,依次输出下一个 token,从而得到最后的结果。
结果
实验结果基本上都处于 SOTA 的水平,不过文中有许多分析的部分,例如实体表示方式之类的。
实验表明长度更短、更类似 BPE 序列的实体会有更好的效果。此外,文中出现越靠后的实体,在 Flat NER 和 Discontinous NER 上召回率都会随之增高,而嵌套实体并没有,作者认为是因为实体间有关联,导致错误传播。
文章最大的贡献点在于提出了一种方式,能够用生成的方式完成各类 NER 任务。
文中出现任何错误或者对于论文内容想要进行探讨,可以在网页最下方找到联系方式邮件联系我,共同学习进步